[인공지능] OpenAI ChatGPT: 오픈AI 챗GPT 모델 기술분석

[인공지능] OpenAI ChatGPT: 오픈AI 챗GPT 모델 기술분석 에 대해 리뷰하려고 합니다.
ChatGPT : Chat bot + GPT = Generative Pre-trained Transformer
OpenAI가 주도하는 ChatGPT는 이름 그대로 Chatbot + GPT = Generative Pre-trained Transformer 개념입니다.
인간과 주고 받는 text 기반의 Chatbot 으로 인터페이스를 갖추고, 인공지능의 구조 및 알고리즘은 GPT로 구현한 것 이네요.
GPT, 대규모 언어모델의 하나로, 사전학습 생성형 변환 알고리즘
GPT (Generative Pre-trained Transformer, 사전학급 생성형 변환)는 LLM(Large Language Model, 대규모 언어모델) 의 한 유형이며, 생성 인공 지능을 위한 탁월한 프레임워크입니다.
자연어 처리 작업 에 사용되는 인공 신경망으로, GPT는 변환기 아키텍처를 기반으로 하며 레이블이 지정되지 않은 텍스트의 대규모 데이터 세트 에 대해 사전 훈련되어 인간과 유사한 새로운 콘텐츠를 생성할 수 있습니다.
2023년 현재 대부분의 LLM은 이러한 특성을 가지며 때로는 광범위하게 GPT라고도 통칭합니다
OpenAI가 주도하는 ChatGPT 모델별 기술적 특징을 중심으로 업데이트한 것 입니다.
GPT-1 (2018)
논문 : Improving Language Understanding by Generative Pre-Training
OpenAPI은 Transformer에 자극받아 GPT-1 논문 "Improving Language Understanding by Generative Pre-Training"을 2018년에 발표합니다.
특징
GPT-1 이전에 대부분의 SOTA LM은 supervised training을 통해 특정한 task를 학습했지만, supervised training에 의해 만들어진 모델은 몇 가지 제한사항을 가지고 있습니다.
특정한 task를 학습하기 위해 많은 양의 label이 달린 데이터가 필요함
이 모델들은 훈련받은 것 이외 task에 대해 일반화할 수 없음
GPT-1 논문은 label이 없는 데이터를 사용하여 Generative 언어모델을 학습한 후, 특정 다운스트림 task(e.g. classification, sentiment analysis, text entailment) 데이터셋으로 모델을 fine-tuning 하는 것을 제안
Unsupervised Learning(Pre-training) + Supervised Learning(Fine-tuning) = Semi-supervised Supervised fine-tuned 모델의 Pre-training을 목적으로 Unsupervised 학습이 사용되었기 때문에 Generative Pre-training 이란 이름이 붙습니다.
구조
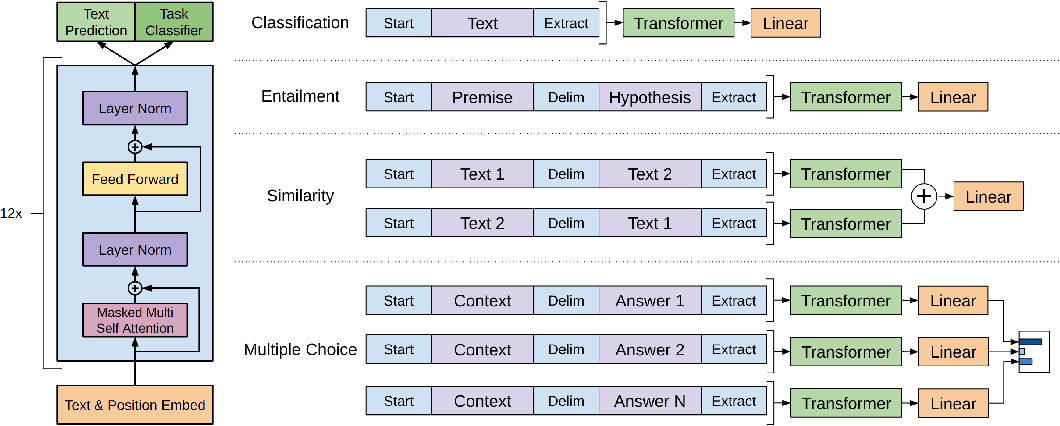
GPT-1은 Transformer의 디코더 12개를 쌓아 올린 구조입니다. (Transformer의 인코더는 사용하지 않는다.)
또한, GPT-1는 Transformer의 디코더 중에서도 Multi-head attention을 제외한 Masked Self-attention과 Feed Forward 네트워크만으로 구성되어 있습니다.
Param: 117 M
구현 Details: 12 decoders, 512 tokens (seq. length)
Dataset: BookCorpus: 4.6 GB. 1.3 Billion Tokens
11K 권 이상의 미출판된 책들을 포함한 데이터셋 (Romance, Fantasy, SF 장르)인 BookCorpus 데이터셋을 사용했는데, 데이터는 downstream task의 테스트 셋에서 발견될 가능성이 낮습니다. 또한 이 corpus(말뭉치)는 연속된 텍스트가 많이 있어서 모델이 광범위한 종속성을 학습하는데 도움이 됩니다.
성능
12개 task 중 9 task에서 Supervised SOTA 모델보다 더 좋은 성능을 보입니다.
또한 Pre-training 덕분에 Q&A , Schema Resolution, Sentiment Analysis와 같은 NLP task의 zero-shot 성능이 향상됩니다.
GPT-2 (2019)
논문 : Language Models are unsupervised multitask learners
2019년도에 발표된 GPT-2 논문의 제목은 “Language Models are unsupervised multitask learners”로 GPT-1보다 더 강력한 언어모델을 학습하기 위해 큰 데이터셋과 더 많은 파라미터를 추가한 것이 특징입니다.
그리고, GPT-2의 가장 큰 목적은 GPT-1에서 존재하는 fine-tuning 없이 unsupervised pre-training 만을 통해 zero-shot으로 down-stream task를 수행할 수 있는 범용 언어모델을 개발하는 것이네요.
특징
GPT-2는 모델 성능을 개선하기 위해 task conditioning, Zero-Shot Learning, Zero Shot Task Transfer를 사용합니다.
Single task를 수행하기 위한 언어 모델의 학습 목표는 P(output|input)이고, GPT-2는 동일한 unsupervised 모델을 사용하여 multi-task을 학습하기 위해 학습 목표를 P(output|input, task)로 수정합니다.
zero-shot learning: zero-shot learning은 예제가 전혀 제공되지 않고 모델이 주어진 instruction을 기반으로 task를 이해하는 zero-shot task transfer의 특별한 경우인데, GPT-1이 수행하는 것처럼 시퀀스를 재정렬하는 대신 모델이 task의 특성을 이해하고 답변을 제공할 것으로 예상되는 형식으로 GPT-2에 대한 입력이 제공됩니다.
구조
GPT-2는 GPT-1에 비해 Layer Normalization 위치가 변경되었는데, GPT-1은 Transformer의 디코더와 같이 LayerNorm (sublayer(x) + x) 형태였는데, x+sub-layer (LayerNorm(x)) 형태로 바뀌게 됩니다.
Params (4개 version): 117M (GPT-1과 동일), 345M, 762M, 1.5B (GPT-2)
구현 Details: 48 decoders, 1024 tokens
Dataset:
WebText (from Reddit links): 40 GB, 15 Billion Tokens
WebText 데이터셋은 Reddit 플랫폼(Social Media Platform)을 스크랩하여 높은 찬성표(min. 3 karma)를 얻은 기사의 모든 아웃바운드 링크(45M 개)에서 수집한 데이터를 정리한 약 8M 건이 약간 넘는 문서를 포함한 데이터(40GB)입니다. 이는 사람들의 휴리스틱 지표를 사용하여 의미 있는 데이터셋을 수집한 것입니다.
성능
“GPT-2는 Zero-Shot 세팅에서 8개 언어 모델링 테스트 데이터셋 중 7개 테스트에서 SOTA 결과 기록합니다.”
총 4개의 다른 파라미터(117M, 345M, 762M, 1.5B)를 가진 모델을 학습하였을 때 파라미터가 커질수록 perplexity가 낮아지는 것을 확인할 수 있었습니다. 이것은 같은 데이터셋을 사용하였을 때 파라미터 개수가 증가할수록 언어 모델의 perplexity가 낮아지며 가장 많은 파라미터를 갖는 모델이 모든 downstream task에 대해서 더 좋은 성능을 갖게 됩니다.
GPT-2 논문은 모델의 용량이 증가할수록 모델 성능이 로그 선형 방식으로 증가하며, 모델의 파라미터 개수가 증가할수록 perplexity가 포화되지 않고 지속적으로 감소함이 증명됩니다. 이 결과는 더 큰 언어 모델일수록 perplexity가 줄어들고, 자연어를 잘 이해할 수 있음을 시사하고 있는데, 이런 GPT-2 논문의 결과는 GPT-3 175B이라는 LLM의 정량적인 실험적 기초가 됩니다.
GPT-3 (2020)
논문 : Language models are few shot learners
GPT-2에서 모델 파라미터와 모델 성능 간의 관계를 실험적인 확인한 OpenAI는 LLM의 필요성을 증명한 “Scaling laws for neural language models” 논문을 2020년 1월에 발표합니다. 직후 OpenAI는 2020년 4월 “Language models are few shot learners” 이란 논문 이름으로 GPT-3을 발표됩니다.
특징
OpenAI는 fine-tuning이 필요하지 않고 약간의 데모만 필요한 매우 강력한 언어모델을 구현하기 위해 175B의 파라미터를 가진 GPT-3 모델을 만듭니다. GPT-3는 175B라는 큰 파라미터 개수와 확장된 데이터셋으로 학습되었기 때문에 zero-shot 및 few-shot 세팅에서 downstream NLP tasks를 잘 수행합니다.
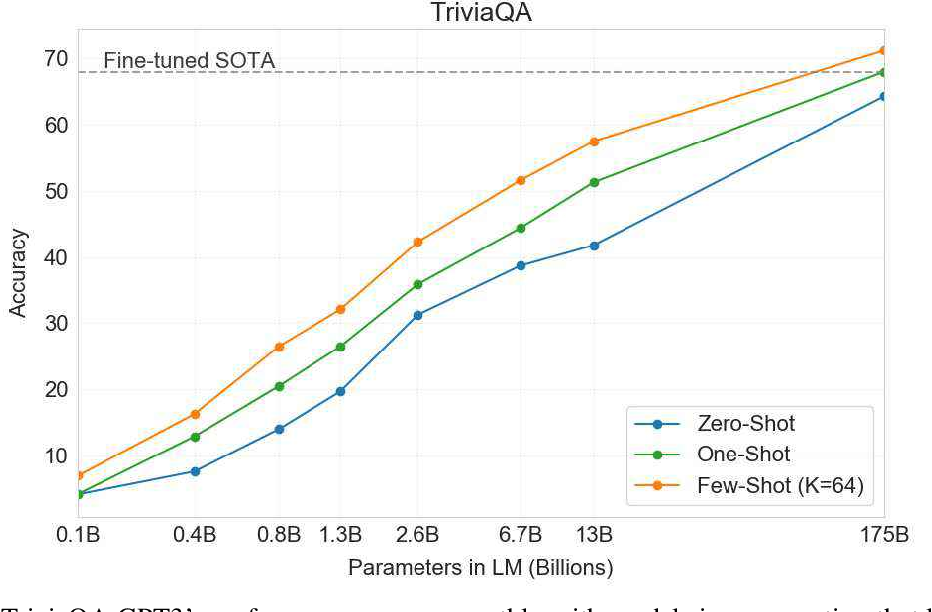
source: Language models are few shot learners 논문
“단어에 섞인 랜덤 한 기호 제거하기”에 대한 GPT-3 모델의 성능을 보여주는데, 다음 2가지 사실을 확인됩니다.
모델 파라미터 크기가 클수록 정확도가 향상된다.
Few-shot에 따른 성능은 예시가 많을수록 정확도가 향상된다.
구조
2020년 OpenAI가 GPT-3 175B을 발표하였을 때 GPT-2 1.5B보다 100배 이상 모델 파라미터 사이즈가 커져 사람들이 충격을 받습니다. GPT-3는 GPT-2와 동일한 모델 구조를 사용하며 GPT-2와 몇 가지 주요 차이점을 설명합니다.
Params: GPT-3는 125M과 같은 small 버전부터 175B 버전까지 존재함
source: Language models are few shot learners 논문
구현 Details: 96 decoders, 2048 tokens
Dataset:
GPT-3는 특정 가중치가 할당된 5개의 서로 다른 말뭉치의 혼합에 대해 학습됩니다. 고품질 데이터셋이 더 많이 샘플링되었으며 1회 이상의 epoch로 학습되었고, 사용된 데이터셋은 Common Crawl, WebText2, Books1, Books2 및 Wikipedia 등이며 데이터셋의 용량은 총 753GB입니다.
성능
GPT-3는 다양한 언어 모델링 및 NLP 데이터 세트에서 평가되었는데, GPT-3는 few-shot 또는 zero-shot 설정에서 LAMBADA 및 Penn Tree Bank와 같은 언어 모델링 데이터 세트에 대해 SOTA 모델보다 우수한 성능을 보입니다.
다른 데이터셋의 경우, SOTA 모델을 이길 수 없었지만 zero-shot SOTA 성능을 향상하게 되었습니다. GPT-3는 또한 비공개 책 질문 답변, 스키마 해결, 번역 등과 같은 NLP 작업을 합리적으로 잘 수행되었으며 종종 SOTA 성능을 능가하거나 미세 조정 모델에 필적하는 성능을 보입니다.
GPT-3.5 (or InstructGPT) (2022)
GPT-3.5라고 불리는 InstructGPT는 2022년 1월에 발표됩니다. GPT-3 기반이지만 정책을 준수하도록 강제함으로써 AI가 인간의 가치와 일치하는 가이드라인 내에서 동작하도록 학습됩니다.
GPT-3을 기본 모델로 GPT-3와 동일한 pre-trained 데이터셋에 추가 fine-tuning이 함께 사용되었고, fine-tuning 단계는 GPT-3 모델에 RLHF (Reinforcement Learning from Human Feedback) 개념을 도입합니다.
GPT-3.5의 최신 버전은 다음과 같은 장점이 있습니다.
더 높은 품질의 글귀가 가능
더 복잡한 명령을 처리
더 긴 형식의 콘텐츠 생성이 더 좋음
구현 Details: 4096 tokens
ChatGPT는 Azure 슈퍼컴퓨터에서 학습된 GPT3.5 모델을 fine-tuning 한 모델로 훨씬 더 엄격한 가이드라인에서 작동하며, 많은 규칙을 강제합니다.
GPT-4 (2023)
GPT- 4 ( Generative Pre-trained Transformer 4 )는 OpenAI에서 만든 다중 모드 대형 언어 모델이며 GPT 기반 모델 시리즈의 네 번째 모델입니다.
2023년 3월에 출시되었으며 유료 챗봇 제품 ChatGPT Plus , OpenAI의 API 및 무료 챗봇 Microsoft Copilot을 통해 공개적으로 제공되었습니다. 변환기 기반 모델 인 GPT-4는 공개 데이터와 "제삼자 제공업체로부터 라이선스를 받은 데이터"를 모두 사용하는 사전 훈련을 사용하여 다음 토큰을 예측하는 패러다임을 사용합니다.
GPT-4의 구조
GPT-2부터 Layer Normalization 위치가 변경되고 Transformer의 decoder의 개수와 context size가 변화되는 것 외 큰 모델 구조의 변경은 없습니다. GPT-4 또한 모델 구조 변경을 통한 최적화보다는 1) 학습 데이터셋 증가, 2) 학습 하이퍼 파라미터 최적화, 3) RLHF 등을 통해 모델 성능을 개선한 것으로 추정됩니다.
GPT-4의 파라미터 크기
Microsoft와 NVIDIA가 만든 MT-NLG는 500B 이상 파라미터를 가진 LLM이지만 SOTA 성능을 발휘하지 못한다. 모델이 커질수록 fine-tuning이 더 많은 비용이 들지만, 더 높은 성능에 도달할 수 있다.
구현 Details: 8192 tokens & 32,768 tokens (4 Turbo)
컨텍스트 창이 8,192개와 32,768개 토큰인 두 가지 버전의 GPT-4를 생산했는데, 이는 각각 4,096개와 2,049개 토큰으로 제한되었던 GPT-3.5와 GPT-3에 비해 크게 개선됩니다. GPT-4의 기능 중 일부 는 OpenAI를 훈련하기 전에 예측되었지만 다른 기능은 다운스트림 확장 법칙의 위반 으로 인해 예측하기 어려웠습니다 .
이전 모델과 달리 GPT-4는 다중 모드 모델입니다. 이미지와 텍스트를 입력으로 사용할 수 있습니다.
[인공지능] 대화형 인공지능 챗봇 모델: ChatGPT
[인공지능] 대화형 인공지능 챗봇 모델: ChatGPT [인공지능] 대화형 인공지능 챗봇 모델: ChatGPT 에 대해 리뷰하려고 합니다. 2022년 11월 OpenAI가 발표한 ChatGPT 혁신이 계속되는데, ChatGPT 대화형 인공지
stephan-review.tistory.com
[인공지능] OpenAI SORA: Text-to-Video 생성형 AI, 소라 공개
[인공지능] OpenAI SORA: Text-to-Video 생성형 AI, 소라 공개 OpenAI SORA: Text-to-Video (News Video) OpenAI SORA: Text-to-Video (source: NBC News) [인공지능] OpenAI SORA: Text-to-Video 생성형 AI, 소라 공개 에 대해 리뷰하려고 합
stephan-review.tistory.com
[인공지능] 챗GPT 스토어, 1월 10일 오픈: ChatGPT Store, Open
[인공지능] 챗GPT 스토어, 1월 10일 오픈: ChatGPT Store, Open [인공지능] 챗GPT 스토어, 1월 10일 오픈: ChatGPT Store, Open 에 대해 리뷰하려고 합니다. 2024년 1월 10일 ChatGPT Store 오픈 ChatGPT는 다양한 기술을 가
stephan-review.tistory.com
[인공지능] Google Gemini Ultra/ Pro/ Nano: 구글 AI 모델 제품군
[인공지능] Google Gemini Ultra/ Pro/ Nano: 구글 AI 모델 제품군 [인공지능] Google Gemini Ultra/ Pro/ Nano: 구글 AI 모델 제품군 에 대해 리뷰하려고 합니다. Google Gemini : OpenAI ChatGPT 능가하는 스펙 Google Gemini는 Go
stephan-review.tistory.com